If rich people died in wars, the media would shift and finally pay attention and label it as a crime - @marvinthe_great
Safe Than Sorry
Abstract
Data is being created all the time promoting the development of enormous datasets, for example, online networking platforms like Twitter. By mining these large datasets, it is conceivable to extricate helpful samples and patterns. The primary concentration of this venture is to break down Twitter and distinguish references to wrongdoing or weakness in the open content of tweets at that point can picture hotspots of wrongdoing onto a guide by utilising the area metadata connected to these tweets. We hopefully aim to gather a correlation of the "crimes talked about" versus the crime statistics of the areas over the years.
Introduction
Better safe than sorry. Your mother most likely shouted those words as she pursued you down the road, bicycle helmet in hand. Be that as it may, the expression turns out to be less fun when you consider this: a violent crime occurs every 45 seconds in India. Possibly it's time to quit fooling around about safety after all?
Would you be concerned if you knew that people tweeted about rape three times as often in your city than in the neighbouring one?
Whether you see infractions or not, they are happening -- and people are talking about them.
To find out what the people are talking about the most, we scoured 40 days worth of Twitter posts in various cities in India for crime-related words. We collated these findings into maps and charts, categorising the crime into five main categories -- violence, theft, sexual assault, drug smuggling, and damage.
Outcomes
The key outcomes of this project:
- Source code which evaluates Twitter for crime-related keywords for each crime type by pattern matching. These include the Tweet text and the URL entity attached to it if any.
- Complete an appropriate statistical test and analyse results to check for any correlation between the two datasets for each of the crime types.
- Analysis of city-wise crime rates to get crime statistics per city.
Methodology
There were three significant steps involved in curating the data for our analysis:
Collecting and Categorising Twitter Data
We've gathered tweets since the past 40 days from seven metropolitan cities in India -- Bengaluru, Chennai, Goa, Hyderabad, Kolkata, Mumbai and New Delhi, based on the search term dictionary defined below.
Crime Category
|
Crime Related Terms
|
Violence
|
‘murder’, ‘killed’, ‘stabbed’, ‘homicide’, ‘drink driving’, ‘harassment’, ‘gunshot’, ‘domestic abuse’, ‘stalking’
|
Theft
|
‘theft’, ‘stolen’, ‘robbed’, ‘burglary’, ‘breaking’ + ‘entering’, ‘nicked’, ‘stealing’
|
Sexual Assault
|
‘rape’, ‘molestation’, ‘sexual assault’, ‘raped’, ‘sexual abuse’
|
Drug Smuggling
|
‘drug’ + ‘possession’, ‘drugs’, ‘possession’, ‘intent to supply’, ‘heroin’, ‘LSD’, ‘cocaine’, ‘smuggle’
|
Damage
|
‘vandalise’, ‘vandals’, ‘arson’, ‘set fire’, ‘destroyed’, ‘vandalize’
|
The collection for each city was done using the GET search/tweets Application Program Interface (API) provided by Twitter using the keywords from the above table and also through scraping. We collected both geo-coded tweets (tweets within a radius of 15 km from the city), and tweets containing the crime and the city in the tweet text.
Sanitising Outputs
Apart from this, there also seemed the need to sanitize tweets. Many (around 75%) of the tweets collected were insignificant and not applicable to our analysis. For example, while searching for the keyword 'murder', we encountered multiple tweets related to the 2004 Bollywood movie named 'Murder'.
We semi-automatically remove the tweets which had nothing to do with crime and were collected because of happenstance. This was done by filtering out tweets with noisy keywords. So, we filtered our total no. of tweets to ~30000.
Collecting Actual Crime Data
To obtain actual crime data, we analysed the 2013 crime statistics available by the Government of India on data.gov.in. We recorded the crime in each city based on our categories.
Analysis
The first step towards the analysis was performing feature extraction on the data. We used the text of the tweet, along with the text from the titles of the URLs (news reports and YouTube videos talking about the incident mostly), as well as any text from images with the tweet. With the text, we extracted the tf-idf features and scaled down to 20 features using Machine Learning Techniques.

Following the feature extraction, we performed clustering on the data we had. Our data set contained data pertaining to each category for each city. To identify the tweets belonging to the same incident, we applied DBSCAN clustering to each data set. The following was the output :



We also made word clouds for the each of the cities, namely Bangalore, Delhi, Mumbai, Kolkata, Hyderabad. The following were the results :
Bangaluru:

Delhi:




With these words clouds, we could get a good idea of which words were used to describe the crimes most for each city, and could present it effectively as well.
Additionally, we also made graphs for each city comparing the frequencies of the actual crime numbers which we found from the site data.gov.in and the number of crimes found via Twitter after data collection, filtering the tweets and extracting features and clustering.
The following were the results:
Bangalore:





In addition to this, we also made graphs for comparing the tweets per category comparing the frequencies of what was being spoken about between genders. We got the gender of the person from his/her name using the api 'Gender API'. The following were the results:
Bangalore:



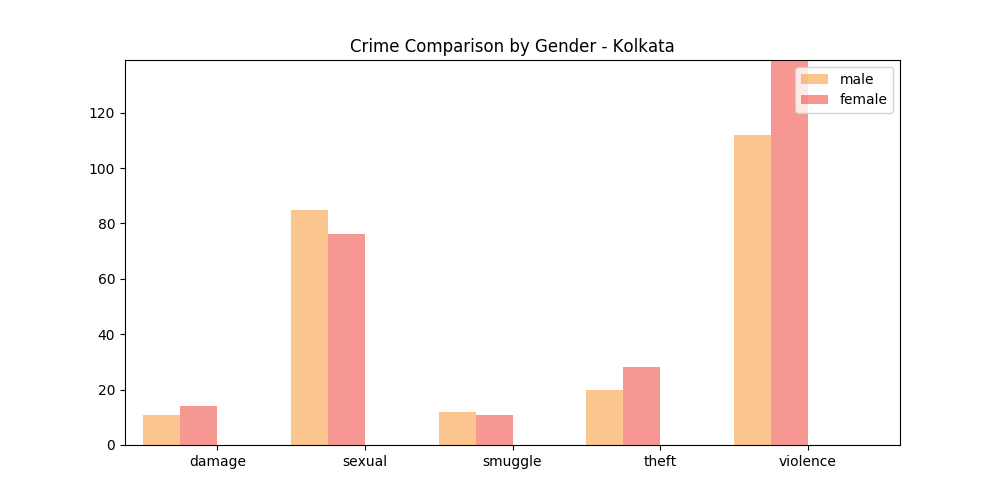

The graphs show that overall, men talk about report more crimes on Twitter than women on Twitter. This is backed by the fact that men have higher social presence on social media. Violent crimes like Murder are more talked about on Twitter by both the genders in all the cities.
Limitations
Because the government doesn’t release actual crime descriptions case-by-case, there is no ground truth to verify the news stories on Twitter. This makes it difficult to figure out if two tweets are talking about the same incident.
Team and Poster Presentation
The following was the project poster we presented on the day of the poster presentation:



Members -
- Parikshit Diwan (2014074)
- Shiven Mian (2015094)
- Madhav Varma (2014061)
- Mridul Gupta (2015061)
Link to the video: https://youtu.be/L3JLAbgCtO0
Comments
Post a Comment