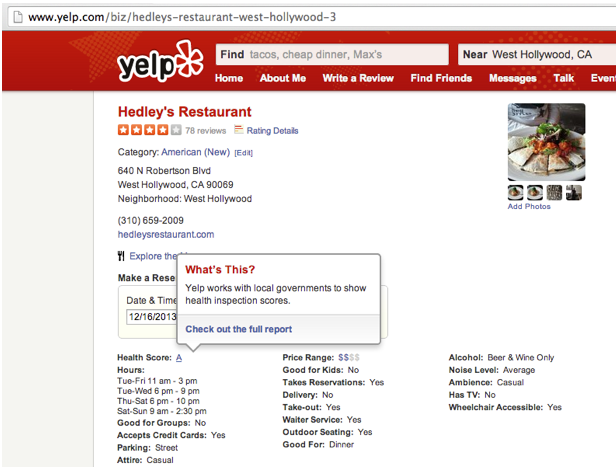
Yelp is an OSN primarily used to popularise the businesses and give reviews about those business. Yelp can be used as an efficient business expander for many upcoming restaurants/spas/saloons who always look for new customers.







Problem Statement
Our main objective of this course project was to target fake/incentivised reviews on yelp and give a credibility score using which a new user of Yelp can get an overall estimate about the restaurant he/she will visit .We developed an application which required an business ID of yelp as an input and it gave the credibility score as the output along with some inferred results in form of graphs
Dataset
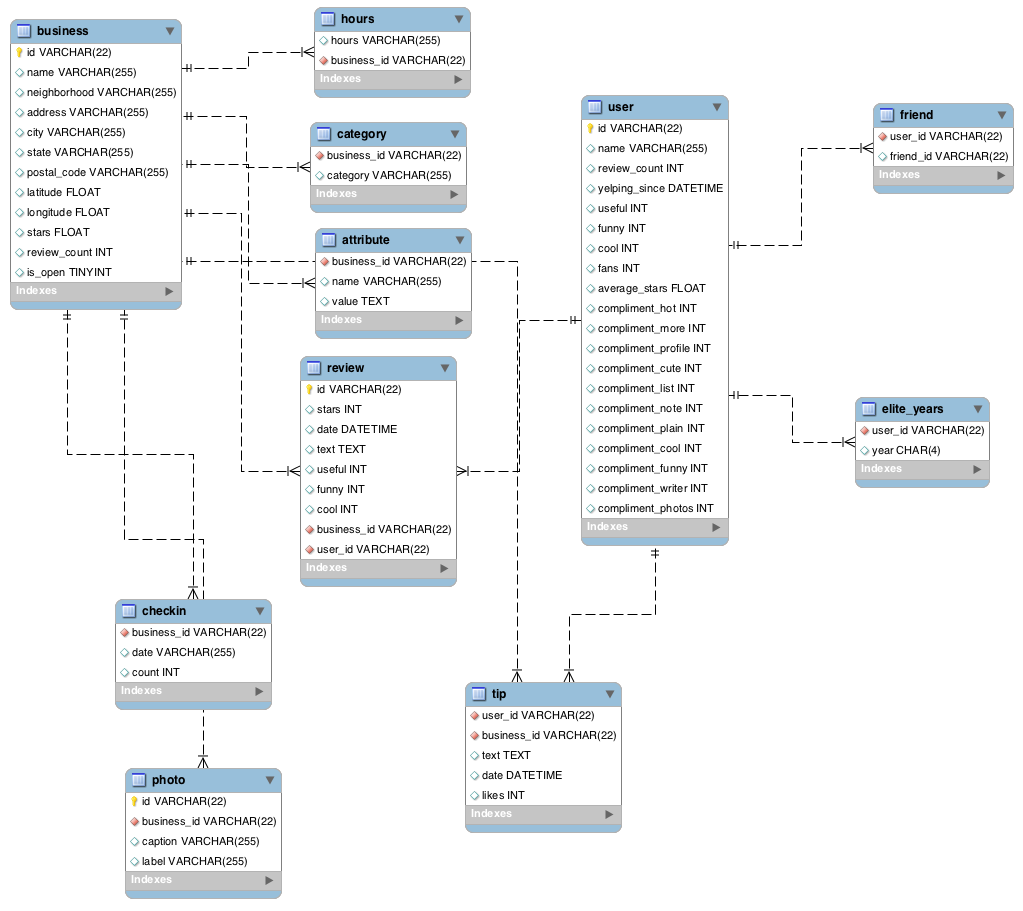
The primary requirement before starting the project was collecting dataset for Yelp business and corresponding reviews and details about the user which post these reviews .The dataset was obtained through Yelp dataset challenge which was available for academic usage and result collections .The database had predefined schema and other data which was not available through schema was web scrapped or collected through API usage.
Data Collection Details
The data available through yelp dataset challenge comprised of over 15 million values and thus for fast retrieval of information and efficient processing data was scaled down to 0.2 million values for each of bussiness ,reviews ,user details .
Methodology
Our process method was a two way strategy comprising of checking for user details and checking for text plagiarism .We gave a score on our application comprising of normalized score values of various parameters and metrics.
So broadly these four metrics were considered while considering for fake review detection .
1. User Rating deviation :It consisted of reducing normalised score of users who gave a score that is hugely deviated from their average score which the user gives
2. Business Rating Deviation :If the business for which fake review detection is targetted showed huge deviation from the overall business score then overall normalised score of that business was reduced significantly.
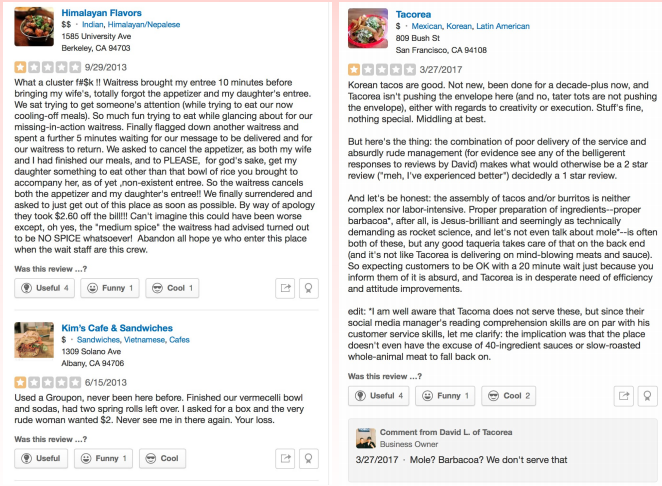
3. User review plagiarism :In this metric we checked for plagiarism for the review which the user had written and checked if certain review existed in our dataset or not .
Review plagiarism was checked based on these parameters:
i) Levenshtein distance: Consisted of minimum no. of string operations required to convert one string to another.
ii) Jaro Winkler distance: Consisted of minimum no. of string addition ,removal,rotation operations to convert one string to another .
iii) NER: This parameter involved searching if certain entities like name , location, references were found to be same across other reviews as well or not.
4. User Location: This parameter consisted of checking for location of user who wrote the review and comparing it with the location of the business.If the distance was found larger than the threshold then that review was flagged .
Results
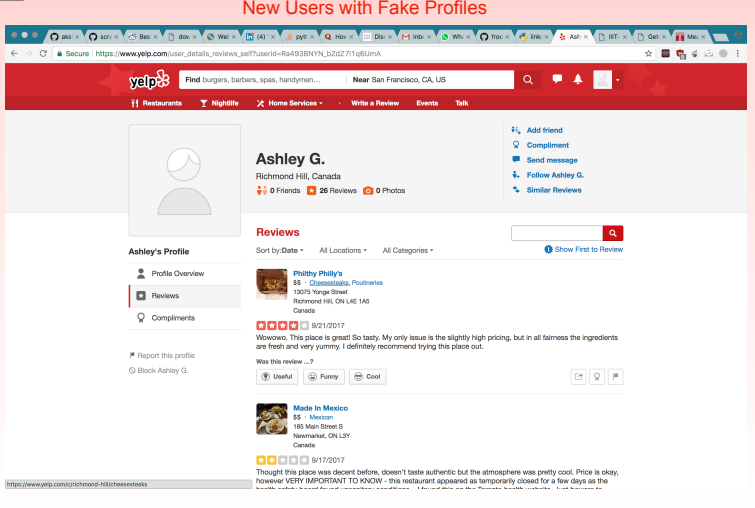
Based on our parameters, we were able to find some profiles/reviews that can be classified as fake with high degree of accuracy.
Presentation and Team
Akash Kumar Gautam (2015011)
Mayank Kumar (2015055)
Sahil Babbar (2013082)
Shyam Agrawal (2015099)
References
- Yelp.com
- https://link.springer.com/chapter/10.1007/978-3-319-11119-3_1
Comments
Post a Comment